
Redacción
Hablar sin cuerdas vocales gracias a un nuevo dispositivo portátil asistido por IA: así es el último avance de bioingenieros de la UCLA (Universidad de Califormia, Los Angeles). El anuncio ha sido publicado en la revista Nature.
Personas con trastornos de la voz, incluidas aquellas con afecciones patológicas de las cuerdas vocales o que se están recuperando de cirugías de cáncer de laringe, a menudo pueden encontrar difícil o imposible hablar. Eso podría cambiar pronto.
Un equipo de ingenieros de la UCLA ha inventado un dispositivo suave, delgado y elástico que mide poco más de 1 pulgada cuadrada y que puede colocarse en la piel fuera de la garganta para ayudar a las personas con cuerdas vocales disfuncionales a recuperar su función vocal.
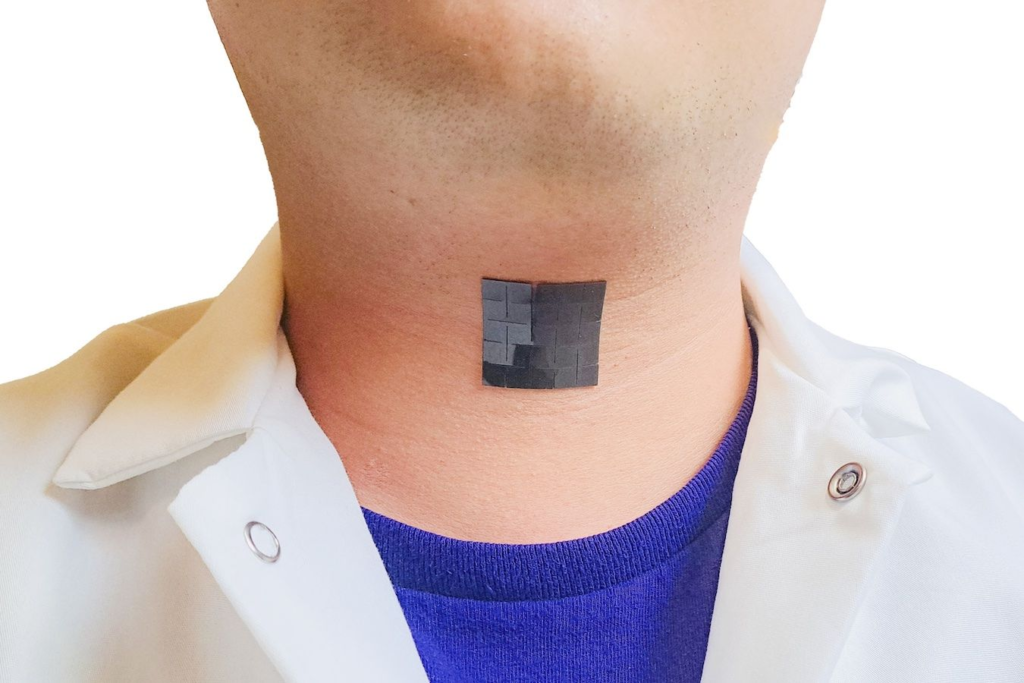

El avance ha sido desarrollado por Jun Chen, profesor asistente de bioingeniería en la Escuela de Ingeniería Samueli de la UCLA, y es el último de los esfuerzos de Chen para ayudar a aquellos con discapacidades. Su equipo desarrolló anteriormente un guante portátil capaz de traducir el lenguaje de señas estadounidense al habla en inglés en tiempo real para ayudar a los usuarios de lenguaje de señas a comunicarse.
El nuevo dispositivo en forma de parche está compuesto por dos componentes. El primero es un sensor autónomo, que detecta y convierte las señales generadas por los movimientos musculares en señales eléctricas de alta fidelidad y analizables; estas señales eléctricas luego se traducen en señales de voz utilizando un algoritmo de aprendizaje automático. El otro, es un componente de actuación, que convierte las señales de voz en la expresión de voz deseada.
Este dispositivo presenta una opción no invasiva
Dr. JUN CHEN
«Las soluciones existentes como los dispositivos electro-laríngeos portátiles y los procedimientos de punción traqueoesofágica pueden ser inconvenientes, invasivos o incómodos», dijo Chen, quien lidera el Grupo de Investigación en Bioelectrónica Portátil en la UCLA, y ha sido nombrado uno de los investigadores más citados del mundo durante cinco años consecutivos.
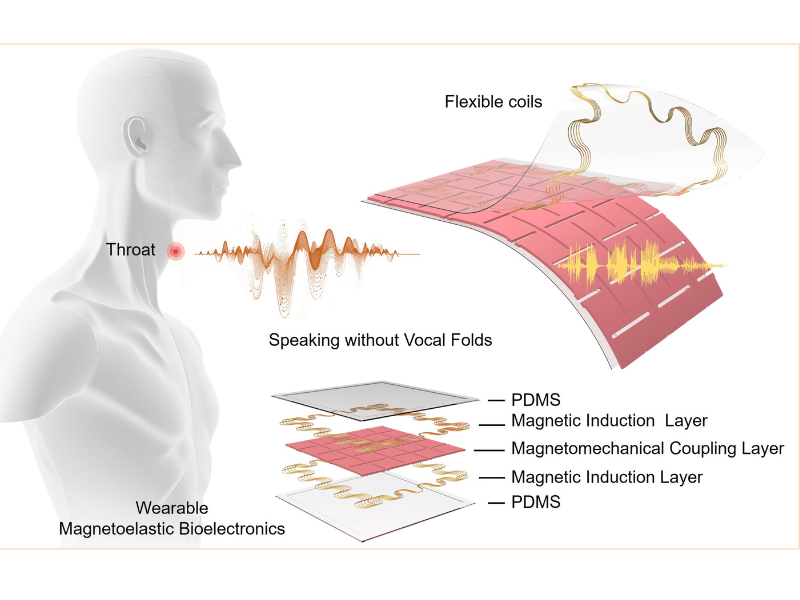
En sus experimentos, los investigadores probaron la tecnología ponible en ocho adultos sanos. Recopilaron datos sobre el movimiento muscular laríngeo y utilizaron un algoritmo de aprendizaje automático para correlacionar las señales resultantes con ciertas palabras. Luego seleccionaron una señal de voz de salida correspondiente a través del componente de actuación del dispositivo. El equipo de investigación demostró la precisión del sistema al hacer que los participantes pronunciaran cinco frases, tanto en voz alta como en silencio, incluyendo «¡Hola, Rachel, ¿cómo estás hoy?» y «¡Te quiero!»
Fuente: lacarabuenadelmundo y ucla.edu